robots.txt란 무엇일까요? robots.txt 파일은 '인터넷 검색엔진 로봇 배제 표준' 이며 일반 텍스트 파일로써 기본적으로 사이트의 루트에 위치합니다. 그리고 그 파일 안에 하나 이상의 규칙을 만들 수 있는데요. 각 규칙은 특정 크롤러가 웹사이트에서 지정된 파일 경로에 액세스 할 수 없게 권한을 차단하거나 허용할 수 있습니다. 한마디로 크롤러의 트래픽을 관리할 수 있게 만들어 주는 규칙 파일입니다.

*크롤러(crawler) : 무수히 많은 웹상에 나뉘어 저장돼 있는 다양한 정보를 수집해 검색대상의 색인으로 포함시키는 기술을 갖는 프로그램을 말합니다. 보통 웹페이지의 내용을 그대로 복제한 뒤 필요한 데이터를 추출하기도 하기 때문에 그 추출한 정보를 이용해 부당이득을 얻기도 하여 법정 분쟁을 야기하기도 합니다.
그렇기 때문에 잘활용해야하는 데요.
이 규칙파일 들을 생성하고 적용하는 방법에 대해 알아봅시다.
▶네이버 웹마스터 도구를 이용한 robots.txt 생성 및 설정
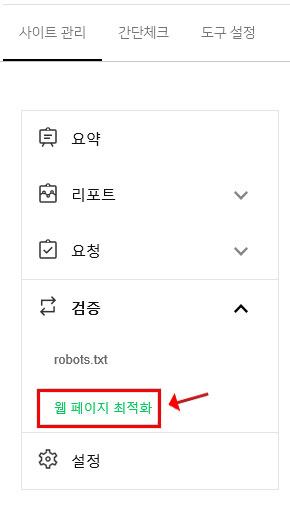
우선 먼저 네이버 서치 어드바이저 사이트에 로그인하여 자신이 등록한 사이트를 클릭 후 웹마스터 도구로 들어갑니다. 그 후 왼쪽에 보이는 검증 메뉴에 웹 페이지 최적화를 클릭하여 자신의 웹페이지 최적화를 검증할 수 있는데요.
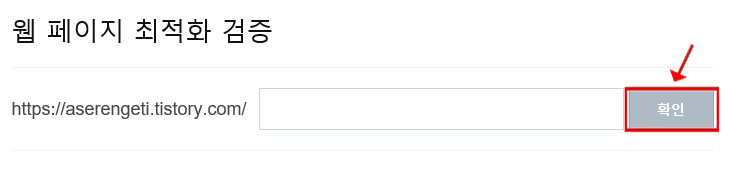
확인 클릭 후 최적화 검증이 시작되고
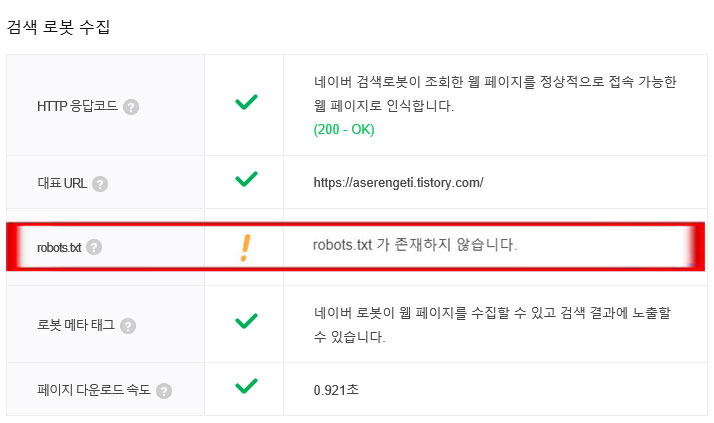
검증 결과는 그림에서 보시다시피 robots.txt가 존재하기 않기 때문에 자신의 티스토리 블로그 사이트를 이용해 robots.txt 파일을 루트 위치에 업로드 가능합니다. 반드시 robots.txt를 생성해야 하는 것이 의무는 아니지만 가끔 원치 않는 크롤링이 들어와 사용자의 정보를 가져갈 수 있기 때문에 홈페이지 관리자 입장에서는 클로러의 아이피를 txt 파일 내용에 첨부하여 차단할 수 있습니다.
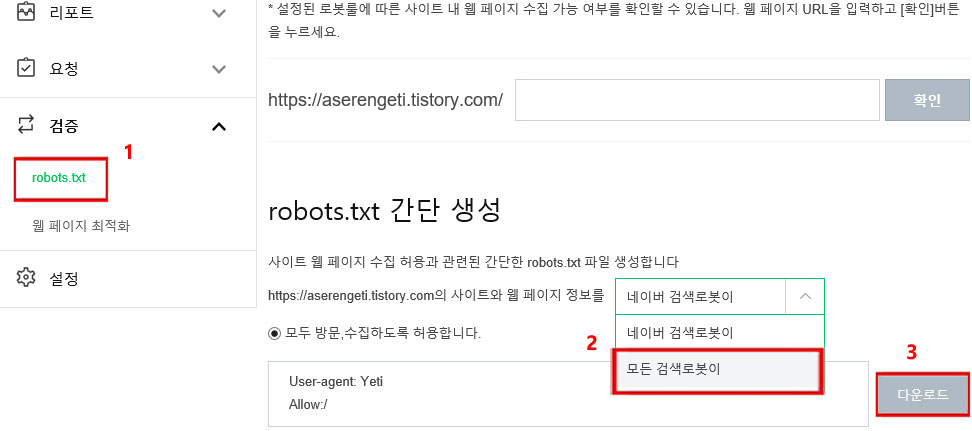
이제 쉽게 네이버 웹마스터도구 메뉴로 robots.txt 파일을 생성할 건데요. 1. 다시 왼쪽 메뉴로 가서 robots.txt를 클릭합니다. 그런 다음 오른쪽에 로봇 룰 검증과 robots.txt 간단 생성 방법이 있는데요. 2. 간단 생성에 앞서 '네이버 검색로봇이'라는 것은 네이버 검색 로봇(Yeti)만 접근 가능한 설정이기 때문에, 포털사이트의 모든 로봇들도 검색할 수 있게 '모든 검색로봇이'로 설정 후 3. 오른쪽에 다운로드를 클릭하여 팝업이 뜨면 저장을 클릭하고 다운로드 위치를 정하고 다운로드합니다. *대표 검색로봇으로는 구글(Googlebot), 구글 이미지(Googlebot-image), Msn(MSNBot), Daum(Daumoa)등이 있습니다.
그 후 설정에 맞게 다운로드된 robots.txt 파일 위치를 잘 기억해주시고.. (대부분은 바탕화면에 다운로드하는 게 작업하기 쉽습니다.)
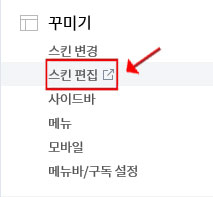
이제 자신의 티스토리 블로그를 접속하여 왼쪽의 관리 메뉴 중 꾸미기의 '스킨 편집' 메뉴를 클릭합니다.
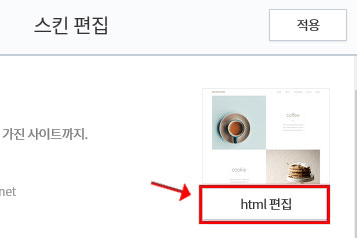
그 후 오른쪽 위 보이는 'html 편집'을 클릭합니다. 대부분은 html 편집을 클릭하면 복잡한 태그를 생각합니다. 하지만 오늘은 간단히 파일만 업로드할 것입니다.
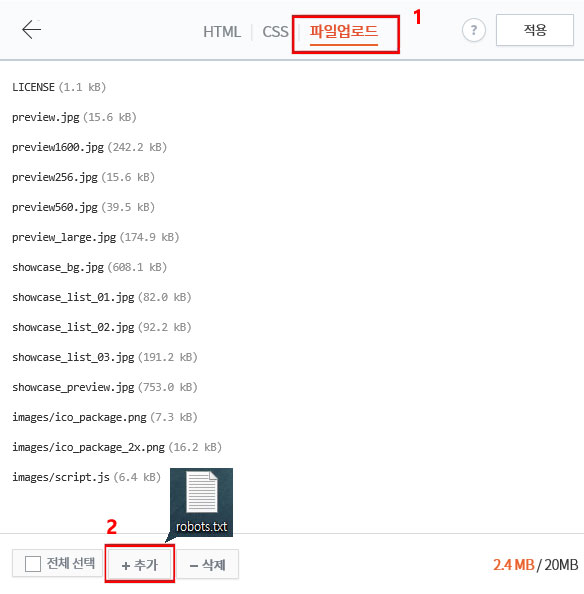
맨 위에 메뉴가 3가지가 더 있는데요. 1. 파일업로드를 클릭해주세요. 그러면 자신의 블로그 사이트 루트에 깔려있는 파일들 보이는데요. 2. 맨 밑에 +추가를 클릭하여 아까 다운로드한 robots.txt 파일을 지정해줍니다.
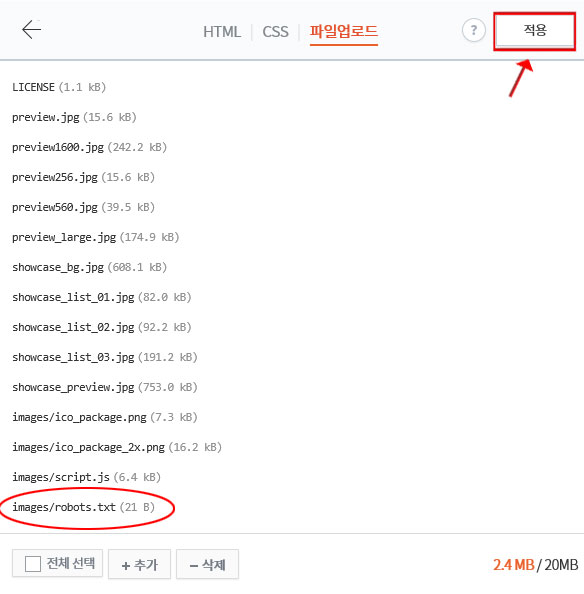
그러면 밑에 파일이 추가된 것이 보이는데요. 마지막으로 적용을 눌러주시면 업로드가 끝이 납니다.
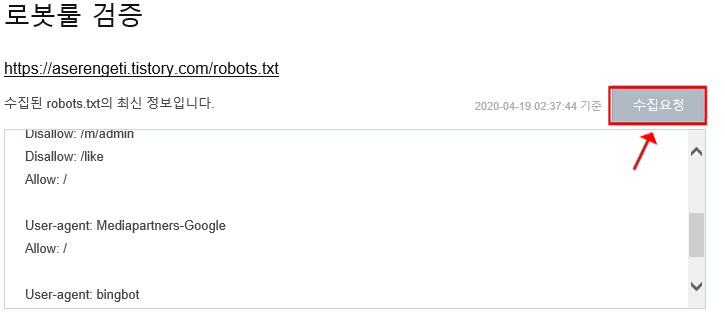
이제 업로드한 로봇 룰 파일이 잘 업로드 됐는지 검증을 해야 하는데요. 다시 네이버 서치 어드바이저 '웹마스터 도구' 메뉴를 가서 검증 메뉴의 robots.txt를 클릭합니다. 오른쪽에 보면 '로봇룰 검증'이라는 글씨가 보이는데요. 오른쪽에 '수집요청'을 클릭하여 검색로봇 수집을 확인하시면 정상적으로 적용된 것을 확인할 수 있습니다.

*더 알아본 봐로는 티스토리는 robots.txt는 자동 생성된다고 합니다. robots.txt는 루트 디렉터리에 설치해야하는데 절대 접근할수 없는 구조이기 때문에 티스토리에서 자동으로 생성 제공합니다. 그렇기 때문에 네이버 웹마스터 도구에 자신의 블로그를 등록하게 되면 robots.txt 파일은 네이버에서 자동으로 수집해 가기 때문에 신경 쓸일은 아닌것 같습니다.
▶메타 태그 사용하기
검색 로봇들은 사이트 방문 시 robots.txt 파일을 읽고 액세스 여부를 판단하는데요. 하지만 접근방지 내용을 robots.txt안에 작성했더라도 무시하고 접근할 수도 있습니다. 그래서 예를 들어 티스토리 같은 경우는 스킨 편집의 html 편집 메뉴에서 메타 태그를 첨가하여 제어할 수 있습니다.

Content에 값에는 "INDEX", "NOINDEX", "FOLLOW", "NOFOLLOW" 가 있는데요. 자신이 원하는 메타 태그를 기입하면 되겠습니다.
| Content 값 | 설명 |
| ALL | 문서 수집, 링크된 문서를 수집 허용 O |
| INDEX | 문서 수집 O |
| NOINDEX | 문서 수집 금지 X |
| FOLLOW | 링크된 문서 수집 허용 O |
| NOFOLLOW | 링크된 문서 수집 금지 X |
▶알아 두면 좋은 robots.txt 규칙
robots.txt를 수정하여 규칙을 만들어 봅시다.
⊙모든 검색 엔진 로봇 허용.
Allow: / |
⊙애드센스 크롤러(Mediapartners-Google)는 모든 폴더에 접근 가능하도록 허용. (애드센스 광고수익을 얻고자한다면 반드시 허용)
Allow: / |
⊙모든 로봇 차단. 하지만 웹사이트의 URL이 크롤링된 적이 없어도 색인이 생성되는 경우가 있습니다.
Disallow: / |
⊙디렉터리 및 디렉터리에 포함된 내용의 크롤링 금지(디렉터리 이름 뒤에 슬래시 입력). 비공개 콘텐츠에 대한 액세스를 차단하는 데 robots.txt를 사용하면 안 됩니다. robots.txt 파일을 통해 금지된 URL은 크롤링되지 않아도 색인이 생성될 수 있으며 robots.txt 파일은 누구나 볼 수 있으므로 비공개 콘텐츠의 위치가 공개될 수도 있습니다.
Disallow: /junk/ |
⊙모든 로봇에 특정 파일 접근을 차단하기
Disallow: /directory/file.html |
⊙특정 형식의 파일 크롤링 금지(예: 차단할 로봇 구글봇(Googlebot), 파일 확장자는 gif)
Disallow: /*.gif$ |
⊙특정 문자열로 끝나는 URL에 적용($ 사용) 예를 들어 차단할 로봇 구글봇(Googlebot), .xls로 끝나는 URL을 모두 차단하기
Disallow: /*.xls$ |
⊙그외 다양하게 조합할수 있습니다.
|
User-agent: googlebot googlebot 로봇만 적용 User-agent: googlebot-news googlebot-news 로봇만 적용 User-agent: * 모든 로봇 적용 |
2020/03/19 - [정보 & 상식/IT] - 구글 애드센스 가입하기
2020/04/03 - [정보 & 상식/IT] - 웹 관리와 구글 검색 유입을 위한 구글 서치 콘솔 등록하는 방법
2020/04/21 - [정보 & 상식/IT] - 내 블로그를 구글검색에 노출하기 위해 꼭 필요한 '키자드 등록'
'정보 & 상식 > IT' 카테고리의 다른 글
| 더 전략적인 블로그 운영을 하기 위한 구글 애널리틱스 가입하기 (6) | 2020.05.02 |
|---|---|
| 내 블로그를 구글검색에 노출하기 위해 꼭 필요한 '키자드 등록' (6) | 2020.04.21 |
| 구글 서치 콘솔에 사이트 맵 제출 하는 방법 (0) | 2020.04.05 |
| 웹 관리와 구글 검색 유입을 위한 구글 서치 콘솔 등록하는 방법 (0) | 2020.04.03 |
| 구글 애드센스 가입하기 (14) | 2020.03.19 |








최근댓글